Digitale Objekte
Digitale Objekte spielen eine zentrale Rolle in den Geisteswissenschaften, insbesondere im Kontext der Digitalisierung, Archivierung und Analyse von kulturellen und historischen Materialien. Sie umfassen digitale Repräsentationen von Texten, Bildern, Artefakten und multimedialen Daten, die durch verschiedene Technologien gespeichert, verarbeitet und zugänglich gemacht werden.
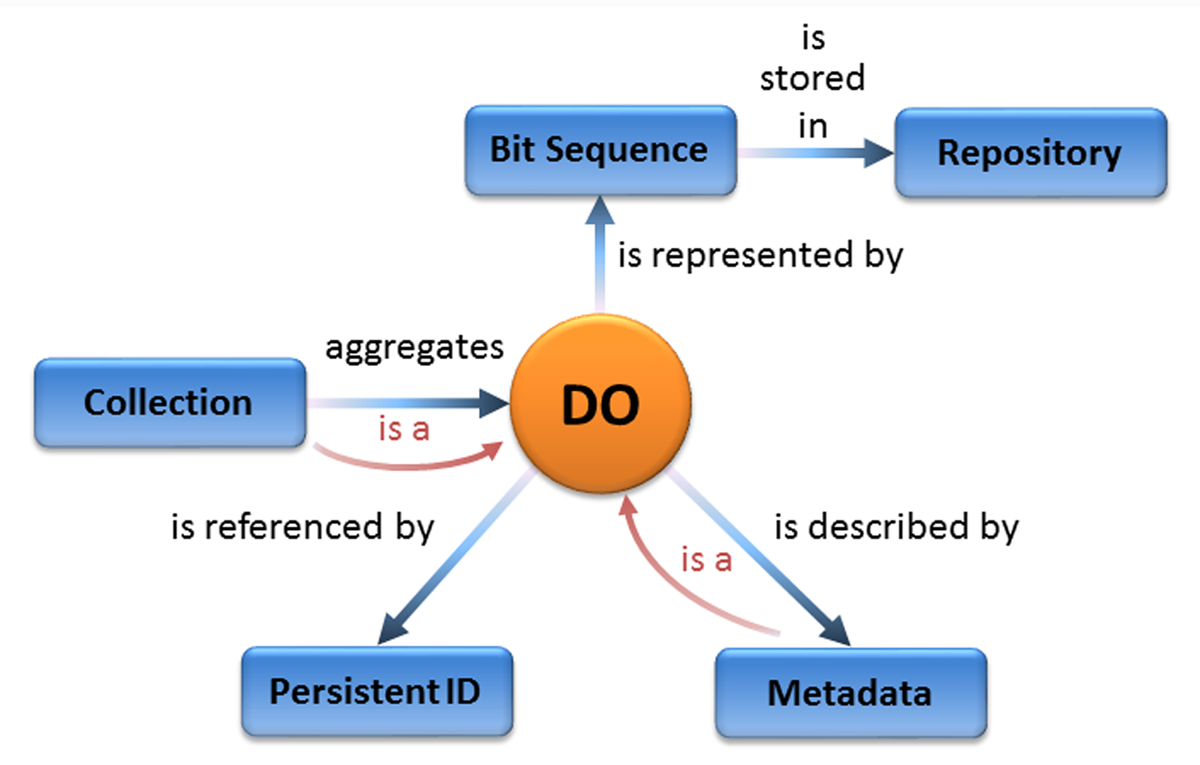
Digitale Objekte sind strukturierte Einheiten aus Daten und Metadaten, die Informationen in einer digitalen Umgebung darstellen. Sie bestehen in der Regel aus:
- Inhalt (z. B. Text, Bild, Ton, Video, 3D-Modelle)
- Metadaten (beschreibende, administrative und technische Informationen)
- Identifikatoren (z. B. DOIs, Handles, URNs zur langfristigen Referenzierbarkeit)
- Strukturinformationen (z. B. Beziehungen zu anderen Objekten oder Hierarchien)
Die Erstellung digitaler Objekte erfolgt durch:
- Scannen und Fotografieren (für Texte, Bilder und Artefakte)
- 3D-Scanning und Photogrammetrie (für materielle Kulturgüter)
- Optische Zeichenerkennung (OCR) (zur Umwandlung von Bildern in durchsuchbare Texte)
- Manuelle und halbautomatische Annotation (zur Erfassung zusätzlicher Informationen)
Digitale Objekte werden in Repositories und Datenbanken gespeichert, die:
- Persistente Identifikatoren für Langzeitreferenzierung nutzen
- Metadatenstandards wie Dublin Core, METS/MODS oder TEI einhalten
- Interoperabilität durch offene Schnittstellen (APIs, Linked Open Data) gewährleisten
Digitale Objekte werden für verschiedene Zwecke genutzt:
- Text- und Datenanalyse (z. B. durch Natural Language Processing, Topic Modeling)
- Wissensvernetzung durch Semantic Web-Technologien
- Visualisierung von historischen Daten (z. B. Netzwerkanalysen, interaktive Karten)
Digitale Objekten werden über verschiedene Kanäle und Plattformen veröffentlicht:
-
Digitale Archive und Repositorien: Hier können wissenschaftliche Arbeiten, Daten und multimediale Objekte, wie Texte, Bilder, Audio- oder Videoaufzeichnungen, veröffentlicht werden. Beispiele sind Zenodo, Archive.org, oder fachspezifische Plattformen wie Europeana oder Digital Public Library of America.
-
Open-Access-Journale: Forschungsergebnisse werden zunehmend in offenen, digitalen Fachzeitschriften veröffentlicht, z. B. JSTOR, Project MUSE oder spezifische Open-Access-Plattformen wie PLOS.
-
Forschungsdatenbanken und digitale Editionsprojekte: In den Geisteswissenschaften gibt es viele Projekte, die Texte und Quellen digital edieren und als Teil von größeren Datenbanken veröffentlichen, z. B. Textgrid, Digital Humanities Initiative oder Perseus Digital Library.
-
Blogs und interaktive Webseiten: Geisteswissenschaftler*innen nutzen zunehmend persönliche oder institutionelle Webseiten und Blogs, um ihre Forschungsergebnisse in interaktiven Formaten oder als offene Diskussionsplattformen zu veröffentlichen.
-
E-Books und digitale Monographien: Digitale Bücher und Monographien sind mittlerweile ein verbreitetes Format für die Veröffentlichung geisteswissenschaftlicher Arbeiten. Dies kann in Form von PDF-Dokumenten oder über spezialisierte Plattformen wie OAPEN geschehen.
Die Archivierung digitaler Objekte ist entscheidend für deren langfristige Zugänglichkeit und Nachnutzbarkeit. Die Hauptansätze zur Archivierung umfassen:
-
Institutionelle Repositorien: Viele Universitäten und Forschungsinstitutionen bieten eigene Repositorien für die Speicherung von wissenschaftlichen Arbeiten und Datensätzen an, wie z. B. HAL (französisches Repository) oder DSpace. Diese Plattformen gewährleisten, dass die Daten langfristig gespeichert und für die Forschung zugänglich bleiben.
-
Langfristige Datenspeicherung: Archivierende Institutionen wie die Bibliothèque nationale de France oder die Deutsche Nationalbibliothek bieten spezielle Archive für wissenschaftliche und historische Daten an. Sie implementieren standardisierte Metadaten und stellen sicher, dass digitale Objekte auch in Zukunft abgerufen werden können.
-
Datenstandards und Formate: Um die Langzeitarchivierung zu gewährleisten, werden bestimmte Dateiformate empfohlen, wie z. B. PDF/A für Texte oder TIFF für Bilder. Dies stellt sicher, dass die Daten in möglichst stabilen und zukunftssicheren Formaten abgelegt werden.
-
Kontinuierliche Sicherung: Viele Archive verwenden Strategien wie die regelmäßige Sicherung der Daten in verschiedenen geografischen Regionen und das Speichern von Metadaten, um die Datenintegrität und die langfristige Nutzbarkeit zu sichern.
FAIR- und CARE-Prinzipien für digitale Objekte
Die FAIR-Prinzipien definieren Kriterien für die nachhaltige Nutzung digitaler Objekte:
- Findable (Auffindbar): Nutzung eindeutiger Identifikatoren und durchsuchbarer Metadaten
- Accessible (Zugänglich): Bereitstellung über standardisierte Protokolle
- Interoperable (Interoperabel): Verwendung offener Standards und kontrollierter Vokabulare
- Reusable (Wiederverwendbar): Klare Lizenzierung und Dokumentation für Nachnutzung
FAIR sorgt dafür, dass digitale Objekte langfristig nutzbar und nachhaltig verwaltet werden.
.
Die CARE-Prinzipien ergänzen FAIR und fokussieren auf den ethischen Umgang mit Daten, insbesondere aus indigenen oder marginalisierten Communities:
- Collective Benefit (Kollektiver Nutzen): Daten sollen Gemeinschaften nutzen
- Authority to Control (Autorität zur Kontrolle): Communities bestimmen über ihre Daten
- Responsibility (Verantwortung): Respektvoller Umgang mit sensiblen Informationen
- Ethics (Ethik): Transparente und faire Forschungsethik
CARE ist besonders relevant für kulturwissenschaftliche Forschungen, bei denen ethische Aspekte eine große Rolle spielen.
Der Einfluss von KI
Die Künstliche Intelligenz hat auch in den Geisteswissenschaften begonnen, eine transformative Rolle zu spielen, insbesondere in den Bereichen der Datenverarbeitung, -analyse und -organisation. Ihre Anwendungen umfassen:
-
Textanalyse und -kategorisierung: KI-basierte Werkzeuge wie maschinelles Lernen (ML) und Natural Language Processing (NLP) ermöglichen es, große Textmengen zu analysieren und zu kategorisieren. Sie können zum Beispiel historische Texte automatisch analysieren, Themen identifizieren oder sogar Übersetzungen erstellen.
-
Automatisierte Inhaltsbearbeitung: In der digitalen Edition von Texten helfen KI-Algorithmen dabei, Texte zu transkribieren und zu bearbeiten. Sie können Handschriften erkennen, Fehler automatisch korrigieren und Versionen von Texten zusammenführen. Tools wie Optical Character Recognition (OCR) werden hierbei genutzt.
-
Visualisierung und Analyse von Netzwerken: KI-Technologien ermöglichen es, historische und kulturelle Daten visuell darzustellen, etwa durch die Analyse von historischen Netzwerken, die Beziehung zwischen Personen, Orten und Ereignissen darstellen.
-
Datenannotation und -kuratierung: Künstliche Intelligenz kann bei der Annotation von Daten helfen, indem sie relevante Metadaten automatisch extrahiert, z. B. durch das Erkennen von Namen, Orten, Daten oder historischen Begriffen in Texten. Dies erleichtert die Datenkuratierung und -organisation erheblich.
-
Forschungshilfe: KI-gestützte Tools können als Unterstützungsinstrumente in der Forschung verwendet werden, um Analysen zu schreiben, Hypothesen zu generieren oder aus historischen Daten Muster zu extrahieren.
-
Ethik und Bias: Ein kritischer Punkt bei der Nutzung von KI ist die Frage nach den ethischen Implikationen und der Verzerrung (Bias) in den verwendeten Algorithmen. Historische und kulturelle Daten könnten in KI-Modellen zu problematischen Ergebnissen führen, wenn diese nicht sorgfältig überprüft und korrekt interpretiert werden.
Das digitale Objekt (DO) ist in eine Struktur anderer wichtiger Datenelemente und Konzepte eingebettet.
https://datascience.codata.org/articles/10.5334/dsj-2020-015/
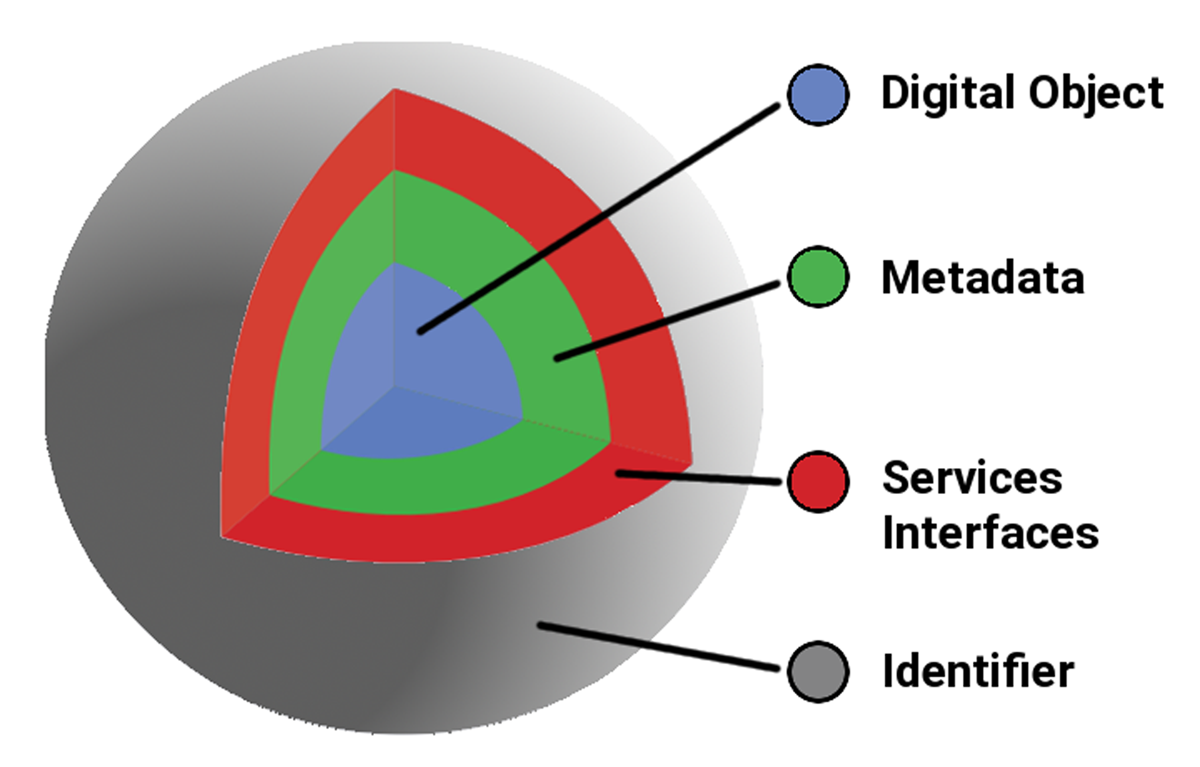
Verkapselung des digitalen Objekts, der Metadaten und der Schnittstellen für Dienste in einem einzigen logischen Element, auf das durch einen dauerhaften Identifikator verwiesen wird. https://datascience.codata.org/articles/10.5334/dsj-2020-015/
Hilfestellung
Handbuch zur Erstellung diskriminierungsfreier Metadaten für historische Quellen und Forschungsdaten