Digitale Repositorien
Ein Repositorium ist eine digitale Plattform zur Speicherung, Verwaltung und Bereitstellung wissenschaftlicher Arbeiten und Forschungsdaten. Studierende und Forschende können hier ihre Publikationen, Abschlussarbeiten oder Forschungsprojekte archivieren und öffentlich zugänglich machen.
Repositorien fördern den offenen Zugang (Open Access) zu wissenschaftlichem Wissen und ermöglichen eine langfristige Sicherung von Forschungsergebnissen. Viele Universitäten bieten eigene Repositorien an, in denen Studierende ihre Arbeiten veröffentlichen können. Ein Beispiel ist das Kölner UniversitätsPublikationsServer (KUPS) der Universität zu Köln.
Durch die Nutzung eines Repositoriums wird die eigene Arbeit auffindbar, zitierfähig und langfristig verfügbar, was besonders für die akademische Laufbahn von Vorteil ist.
Es gibt verschiedene Arten von Repositorien, die sich nach ihrem Zweck und ihrer Zielgruppe unterscheiden:
-
Institutionelle Repositorien
- Diese werden von Universitäten oder Forschungseinrichtungen betrieben, um wissenschaftliche Arbeiten ihrer Mitglieder zu archivieren und zugänglich zu machen.
- Beispiel: KUPS (Kölner UniversitätsPublikationsServer) für die Universität zu Köln.
-
Disziplinäre Repositorien
- Diese spezialisieren sich auf bestimmte Fachbereiche und sammeln wissenschaftliche Publikationen aus einer bestimmten Disziplin.
- Beispiel: arXiv für Physik, Mathematik und Informatik oder Europe PMC für biomedizinische Forschung.
-
Allgemeine Online-Repositorien
- Diese sind nicht an eine bestimmte Institution oder Disziplin gebunden und stehen Forschenden weltweit offen. Sie ermöglichen eine breitere Verbreitung wissenschaftlicher Arbeiten.
- Beispiel: Zenodo (gehostet vom CERN)
Der EU finanzierte und durch das OpenAIRE-Konsortium betreute Online-Speicherdienst Zenodo ist hauptsächlich für die Wissenschaft gedacht und speichert wissenschaftsbezogene Datensätze, Software, Publikationen, Berichte, Präsentationen, Videos usw. Die dort gespeicherten Inhalte sind zitierfähig, da sie eine zitierbare DOI haben und der Repository-Dienst GitHub integriert ist. Es gibt eine Integration von ORCID, eine Nutzerstatistik und verschiedene Lizenzoptionen.
Persistente Identifier
Was ist ein sinnvoller Identifier für digitale Kulturgüter?
Die zentrale Funktion von Identifieren besteht darin, eine eindeutige Referenz für Objekte oder Daten zu schaffen, um deren Verfolgbarkeit und Zuordnung zu gewährleisten.
Ein persistenter Identifier (auch "Permanenter Bezeichner" genannt) ist ein eindeutiger und dauerhafter Verweis auf eine Ressource, wie etwa ein Dokument, Datensatz, Bild, Video oder eine andere Art von digitalen Objekten. Im Gegensatz zu herkömmlichen Identifiern, die sich ändern oder veralten können (wie z. B. URLs), ist ein persistenter Identifier darauf ausgelegt, langfristig stabil zu bleiben, auch wenn die zugrunde liegende Ressource oder deren Speicherort geändert wird.
Eigenschaften eines persistenten Identifiers
- Eindeutigkeit: Jeder Identifier ist eindeutig und verweist auf genau eine Ressource.
- Persistenz: Der Identifier bleibt über einen langen Zeitraum stabil, auch wenn sich die Ressourcen-URL oder der Speicherort ändert.
- Unveränderlichkeit: Einmal zugewiesen, ändert sich der Identifier selbst nicht.
- Auflösbarkeit: Der Identifier kann in der Regel durch ein System oder einen Dienst in den aktuellen Speicherort der Ressource aufgelöst werden (ähnlich wie ein DNS-System).
Beispiele für persistente Identifier
- DOI (Digital Object Identifier): Ein weit verbreiteter Standard zur Kennzeichnung digitaler Objekte, insbesondere wissenschaftlicher Publikationen. Ein DOI verweist immer auf das gleiche Werk, auch wenn sich dessen Speicherort ändert. siehe unten
- Beispiel:
doi:10.1000/182
- Beispiel:
- URN (Uniform Resource Name): Ein URI (Uniform Resource Identifier), der als dauerhafte Referenz für Ressourcen verwendet wird. URNs sind speziell dafür gedacht, über lange Zeiträume stabil zu bleiben. siehe unten
- Beispiel:
urn:isbn:0451450523
- Beispiel:
- Handle System: Ein weiteres System, das persistente Identifier bereitstellt. Handles werden häufig für die Verwaltung von digitalen Ressourcen in Repositorien verwendet. siehe DSpace
- Beispiel:
hdl:20.1000/100
- Beispiel:
- ARK (Archival Resource Key): Ein persistent Identifier, der oft in Archiven und Bibliotheken verwendet wird, um auf digitale und physische Objekte zu verweisen.
- Beispiel:
ark:/13030/tqb3kh
- Beispiel:
Persistente Identifier sind besonders wichtig in Bereichen wie:
- Wissenschaft und Forschung: Um sicherzustellen, dass akademische Publikationen, Forschungsdaten und andere digitale Inhalte langfristig auffindbar bleiben.
- Bibliotheken und Archive: Für die dauerhafte Verwaltung von digitalen und physischen Sammlungen.
- Digitale Repositorien: Um sicherzustellen, dass Inhalte auch bei technischen Änderungen (z. B. Migration auf neue Systeme) auffindbar bleiben.
Persistente Identifier gewährleisten also, dass digitale Inhalte auch in Zukunft zuverlässig aufgerufen werden können, was für die Langzeitarchivierung und das Forschungsdatenmanagement essenziell ist.
Konzept: URI URN URL Video
Entscheidend: Persistent Identifier (DOI, Kontext FDM), der die Bestandteile eines digitalen Objektes über Datei- und Speichergrenzen hinaus zusammenhält.
Digital Object Architecture (DOA)
Diese ist eine Architektur, die speziell entwickelt wurde, um digitale Objekte zu verwalten und zu integrieren, insbesondere in großen, verteilten Systemen, die langfristige digitale Archivrepositories, Datenbanken oder andere digitale Bestände betreffen.
Die Digital Object Architecture zielt darauf ab, digitale Objekte über ihre gesamte Lebensdauer hinweg zu verwalten und zu sichern. Sie stellt sicher, dass digitale Objekte und ihre Metadaten zuverlässig gespeichert, abgerufen und genutzt werden können, auch über längere Zeiträume hinweg.
Wichtige Aspekte
-
Digitale Objekte als zentrale Entität
- In der DOA sind digitale Objekte die primären Entitäten, die gespeichert und verwaltet werden. Ein digitales Objekt kann ein beliebiges digitales Element sein, wie zum Beispiel eine Datei, ein Datensatz, ein Bild, ein Video oder sogar eine Sammlung von Inhalten. Jedes digitale Objekt hat eine eindeutige Identifikation (meist eine DOI – Digital Object Identifier, siehe oben), die es ermöglicht, das Objekt über verschiedene Systeme hinweg zu referenzieren und darauf zuzugreifen.
-
Metadaten und Provenienz
- Die DOA betont die Bedeutung von Metadaten und Provenienz. Jedes digitale Objekt wird zusammen mit Metadaten gespeichert, die Informationen über das Objekt selbst (z.B. Erstellende, Erstellungsdatum) sowie seine Historie und Nutzung (Provenienz) enthalten. Diese Metadaten ermöglichen eine korrekte Verwaltung, Suche und langzeitige Archivierung.
-
Interoperabilität und Standards
- Die DOA nutzt weit verbreitete Standards, um Interoperabilität zwischen verschiedenen Systemen zu gewährleisten. Sie ist darauf ausgelegt, dass digitale Objekte über verschiedene Archive, Datenbanken und Anwendungen hinweg ausgetauscht und zugänglich gemacht werden können.
-
Zugriffsmechanismen und Persistenz
- Die DOA stellt sicher, dass digitale Objekte zugänglich und langfristig bewahrt werden können. Sie unterstützt sowohl Content-Management-Mechanismen (um auf Objekte zuzugreifen und sie zu verwalten) als auch Archivierungsprozesse (um die Langlebigkeit und Persistenz der Objekte zu garantieren).
-
Dezentralisierte Speicherung
- Ein zentraler Bestandteil der DOA ist die dezentrale Speicherung von digitalen Objekten. Digitale Objekte können an verschiedenen Orten gespeichert werden, aber ihre Identität und Metadaten bleiben durch die Architektur konsistent, sodass sie auch in verteilten Systemen auffindbar und zugänglich bleiben.
-
Services und Operations
- Die DOA umfasst nicht nur die Speicherung von digitalen Objekten, sondern auch die Bereitstellung von Diensten zur Verwaltung und Interaktion mit diesen Objekten. Diese Dienste umfassen u.a. die Suche, Zugriffssteuerung, Versionierung und Authentifizierung von Objekten.
-
Langfristige Archivierung
- Ein zentrales Ziel der Digital Object Architecture ist die Langzeitbewahrung von digitalen Inhalten. Dies betrifft insbesondere die Herausforderung, digitale Objekte über Jahrzehnten oder sogar Jahrhunderte hinweg zugänglich zu halten, auch wenn sich die zugrunde liegende Technologie oder das Format der Objekte ändern.
Anwendungsgebiete der DOA
-
Digitale Bibliotheken und Archive: DOA ist ideal für den Aufbau von Repositories, die langfristige digitale Bestände und historische Dokumente verwalten müssen.
-
Forschungseinrichtungen: DOA wird auch oft in wissenschaftlichen und akademischen Kontexten eingesetzt, um Forschungsdaten und Publikationen zu verwalten und sicherzustellen, dass sie für die Zukunft zugänglich bleiben.
-
Datenmanagement: Sie wird häufig verwendet, um große Mengen an Forschungsdaten, Bildern, Videos und anderen digitalen Ressourcen zu strukturieren und zu archivieren.
-
Urheberrecht und Digital Rights Management (DRM): Durch ihre Verwaltung von Metadaten und Provenienz kann DOA auch im Kontext von Rechten und Lizenzen von digitalen Objekten eine wichtige Rolle spielen.
Die Digital Object Architecture stellt ein robustes Modell dar, um digitale Objekte systematisch zu verwalten, zu archivieren und ihre Zugänglichkeit langfristig zu sichern. Sie stellt sicher, dass digitale Objekte in einer dezentralisierten und interoperablen Weise behandelt werden können und dabei ihre Integrität und Authentizität über die Zeit hinweg gewahrt bleiben. Sie ist besonders wichtig in Szenarien, die eine langfristige Datenspeicherung und -verfügbarkeit erfordern, wie in Bibliotheken, Archiven oder bei der Archivierung von Forschungsdaten.

Die Open-Access-Bewegung (OA) ist eine weltweite Initiative, die sich für den freien und uneingeschränkten Zugang zu wissenschaftlichen Publikationen, Forschungsergebnissen und anderen akademischen Ressourcen einsetzt. Ziel ist es, wissenschaftliches Wissen für alle zugänglich zu machen, ohne finanzielle, technische oder rechtliche Barrieren.
Definition
Open Access bedeutet, dass wissenschaftliche Publikationen online kostenlos und ohne Einschränkungen verfügbar sind. Dadurch können Wissenschaftler*innen, Studierende, politische Entscheidungsträger*innen und die breite Öffentlichkeit auf Forschungsergebnisse zugreifen, ohne für den Zugang bezahlen zu müssen.
Die Bewegung entstand als Reaktion auf die Kostenbarrieren traditioneller wissenschaftlicher Publikationen, die oft nur über teure Zeitschriftenabonnements oder institutionelle Lizenzen zugänglich sind.
Merkmale
- Freier Zugriff: OA-Publikationen sind für alle Nutzenden ohne Bezahlung oder Registrierung frei zugänglich.
- Wiederverwendbarkeit: Viele Open-Access-Publikationen sind unter Lizenzen wie Creative Commons (CC-BY) veröffentlicht, die die Nutzung, Verbreitung und Bearbeitung erlauben.
- Digitale Verfügbarkeit: Open-Access-Inhalte sind über Online-Plattformen abrufbar, oft in institutionellen oder thematischen Repositorien.
- Langfristige Archivierung: OA-Beiträge werden häufig in digitalen Archiven und Repositorien gespeichert, um dauerhaften Zugriff zu gewährleisten.
Formen
Goldener Open Access
- Die Publikation ist sofort frei verfügbar.
- Die Finanzierung erfolgt oft über Publikationsgebühren (Article Processing Charges, APCs), die von Autoren oder deren Institutionen bezahlt werden.
Grüner Open Access
- Die Publikation erfolgt zuerst in einer kostenpflichtigen Zeitschrift, aber eine Zweitveröffentlichung in einem Repositorium (z.B. einer Universitätsbibliothek) ist erlaubt.
- Autoren können oft eine Preprint- oder Postprint-Version (Vorabdruck/Nachdruck) frei zugänglich machen.
Hybrider Open Access
- Kombination aus traditionellem Verlagsmodell und OA.
- Autor*in kann gegen eine Gebühr einzelne Artikel in einer kostenpflichtigen Zeitschrift Open Access schalten.
- Kritik: Oft sehr hohe Gebühren, sogenanntes „Double Dipping“ (Verlage verlangen Geld für Abonnements und OA-Gebühren).
Diamantener Open Access (Platin-OA)
- Veröffentlichungen sind ohne Kosten für Autor*innen und Leser*innen verfügbar.
- Finanzierung erfolgt durch öffentliche Institutionen oder Universitäten.
Vorteile
- Freier Zugang zu Wissen → Wissenschaftliche Informationen sind für alle verfügbar, unabhängig von finanziellen Ressourcen.
- Beschleunigte Forschung → Wissenschaftler*innen können schneller auf neueste Erkenntnisse zugreifen.
- Höhere Sichtbarkeit und Zitierhäufigkeit → OA-Artikel werden häufiger gelesen und zitiert.
- Geringere Kosten für Bibliotheken → Universitäten müssen weniger für teure Zeitschriftenabonnements zahlen.
- Gesellschaftlicher Nutzen → Bürger*innen, Unternehmen und Politiker*innen können wissenschaftliche Erkenntnisse nutzen.
Herausforderungen und Kritikpunkte
- Finanzierung der Open-Access-Modelle → Wer zahlt für die Veröffentlichung? (APCs, institutionelle Förderungen).
- Qualitätskontrolle → Manche OA-Zeitschriften haben ein schwaches Peer-Review, es gibt sogenannte Predatory Journals.
- „Pay-to-Publish“-Problem → Wissenschaftler*innen aus finanziell schwächeren Institutionen haben Schwierigkeiten, APCs zu bezahlen.
- Akzeptanz in bestimmten Disziplinen → In manchen Fachgebieten ist OA weniger etabliert.
Wichtige Open-Access-Initiativen
- Budapest Open Access Initiative (BOAI, 2002)→ Erste umfassende Definition von Open Access.
- Berlin Declaration on Open Access (2003) → Unterstützt von vielen Universitäten weltweit.
- Plan S (seit 2018)→ Strenge OA-Pflicht für durch öffentliche Gelder finanzierte Forschung in Europa.
Open Archives Initiative (OAI)

Die Open Archives Initiative (OAI) ist eine internationale Bewegung, die sich auf die Entwicklung von Interoperabilitätsstandards für den offenen Zugang zu digitalen wissenschaftlichen Inhalten konzentriert. Sie wurde gegründet, um wissenschaftliche Repositorien und digitale Bibliotheken besser miteinander zu vernetzen, sodass deren Inhalte leichter auffindbar und zugänglich sind.
Ziele der Open Archives Initiative
- Standardisierung: Entwicklung von technischen Protokollen, um den Austausch von Metadaten zwischen digitalen Archiven und Repositorien zu erleichtern.
- Interoperabilität: Ermöglichung des automatisierten Datenaustauschs zwischen wissenschaftlichen Datenbanken, Bibliotheken und Archiven.
- Freier Zugang zu Forschungsergebnissen: Förderung des Open-Access-Prinzips, indem wissenschaftliche Arbeiten besser durchsuchbar und zugänglich werden.
- Verknüpfung von Repositorien: Digitale Bibliotheken, Universitäten und Forschungsinstitutionen können ihre Sammlungen miteinander vernetzen.
OAI-Protokolle & Standards
Die wichtigste technische Entwicklung der OAI ist das OAI-PMH (Open Archives Initiative Protocol for Metadata Harvesting) und OAI-ORE (Open Archives Initiative Object Reuse and Exchange).
- Technisches Protokoll zur automatisierten Sammlung von Metadaten aus digitalen Repositorien.
- Ermöglicht Suchmaschinen und Bibliothekskatalogen (z. B. Google Scholar, BASE), auf Inhalte verschiedener Plattformen zuzugreifen.
- Zwei Hauptakteur*innen:
- Datenanbieter*innen (Data Providers): Institutionen oder Archive, die Metadaten bereitstellen.
- Dienstanbieter*innen (Service Providers): Suchmaschinen oder Plattformen, die diese Metadaten abrufen und durchsuchen.
- Standard für die Verknüpfung und Wiederverwendung digitaler Objekte (z. B. Artikel, Daten, Bilder).
- Erleichtert die Verwaltung und den Austausch komplexer Inhalte in Repositorien.
Vorteile der Open Archives Initiative
- Vernetzung von Open-Access-Repositorien → Wissenschaftliche Publikationen erhalten eine größere Reichweite.
- Automatisierter Metadatenaustausch → Bibliotheken und Suchmaschinen können effizient auf Metadaten zugreifen.
- Förderung von Open Access → Wissenschaftliche Arbeiten werden global leichter zugänglich.
- Interoperabilität zwischen verschiedenen Plattformen → Universitäten und Forschungszentren können ihre Inhalte systemübergreifend vernetzen.
Beispiele für OAI-PMH-kompatible Repositorien
- arXiv (Physik, Mathematik, Informatik)
- PubMed Central (Medizin)
- BASE (Bielefeld Academic Search Engine)
- Europeana (Europäische digitale Bibliothek)
- Dspace (Open-Source-Software für digitale Repositorien)
Herausforderungen & Kritik
- Technische Umsetzung erfordert Ressourcen → Kleine Institutionen haben oft Schwierigkeiten, OAI-PMH zu implementieren.
- Qualität der Metadaten variiert → Uneinheitliche Metadaten-Standards können die Suche erschweren.
- Missbrauch durch unseriöse Zeitschriften → Manche Predatory Journals nutzen OAI-PMH, um ihre Inhalte breiter zu streuen.
OAI Protocol for Metadata Harvesting (OAI-PMH)
Ein Standard für den Austausch von Metadaten
Das Open Archives Initiative Protocol for Metadata Harvesting (OAI-PMH) ist ein weit verbreitetes Protokoll für den standardisierten Austausch von Metadaten zwischen digitalen Repositorien und anderen Diensten. Es ermöglicht es, wissenschaftliche Publikationen, Forschungsdaten oder andere digitale Objekte über verschiedene Plattformen hinweg auffindbar und zugänglich zu machen.
Funktionsweise von OAI-PMH
OAI-PMH basiert auf einem Client-Server-Modell, bei dem sogenannte Data Provider (Datenanbieter) ihre Metadaten für Service Provider (Dienstanbieter) bereitstellen. Dies geschieht über eine standardisierte HTTP-Schnittstelle, die auf XML und dem Dublin Core Metadatenschema basiert.
Die wichtigsten Bestandteile des Protokolls sind:
- Data Providers: Institutionelle oder disziplinäre Repositorien (z. B. KUPS, arXiv), die ihre Metadaten öffentlich zugänglich machen.
- Service Providers: Suchmaschinen oder Bibliothekskataloge (z. B. BASE, OpenAIRE), die diese Metadaten sammeln, indexieren und durchsuchbar machen.
- OAI-PMH Requests: Abfragen, mit denen Metadaten in standardisierten Formaten wie Dublin Core oder MARCXML abgerufen werden können.
Vorteile von OAI-PMH
- Interoperabilität: Ermöglicht die Vernetzung verschiedener Repositorien und verbessert die Sichtbarkeit wissenschaftlicher Arbeiten.
- Effizienz: Metadaten werden automatisch gesammelt, ohne dass Nutzer oder Bibliotheken manuell suchen müssen.
- Standardisierung: Einheitliche Metadatenformate erleichtern die Nachnutzung durch Suchmaschinen und Forschungsportale.
Anwendungsbereiche
- Bibliotheken & Repositorien: OAI-PMH wird von vielen Universitätsbibliotheken genutzt, um wissenschaftliche Publikationen für Suchmaschinen wie BASE oder Europeana bereitzustellen.
- Open Access Plattformen: Dienste wie OpenAIRE oder CORE aggregieren Metadaten aus Tausenden von Repositorien weltweit.
- Digitale Geisteswissenschaften: Projekte zur Digitalisierung von Kulturerbe nutzen OAI-PMH, um digitale Sammlungen leichter auffindbar zu machen.
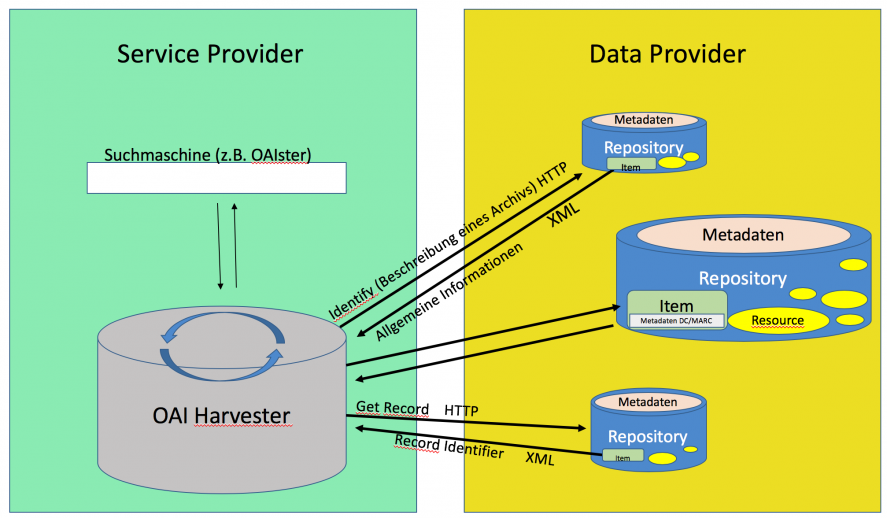
OAI-PMH ist ein essenzielles Protokoll für den Austausch von wissenschaftlichen Metadaten. Es ermöglicht eine bessere Vernetzung und Auffindbarkeit von Publikationen, insbesondere im Open-Access-Bereich. Gerade für Studierende und Forschende ist es eine zentrale Technologie, um wissenschaftliche Arbeiten effizient und nachhaltig zugänglich zu machen.
OAIster wurde von der University of Michigan entwickelt und stellt über die Website www.oaister.org eine Suchmaschine zur Verfügung, die die Metadaten von allen Data Providern in Form von durchsucht.
OAI-ORE: Standard für die Strukturierung und Wiederverwendung digitaler Objekte
Das OAI Object Reuse and Exchange (OAI-ORE)-Protokoll ist ein Standard, der die Strukturierung, Identifikation und den Austausch komplexer digitaler Objekte ermöglicht. Es wurde von der Open Archives Initiative (OAI) entwickelt und ergänzt das OAI-PMH-Protokoll, indem es sich nicht nur auf Metadaten konzentriert, sondern auch auf die Beziehungen zwischen digitalen Ressourcen.
Warum OAI-ORE?
Während OAI-PMH vor allem Metadaten für die Auffindbarkeit bereitstellt, geht OAI-ORE einen Schritt weiter:
- Es modelliert komplexe digitale Objekte, die aus mehreren Bestandteilen bestehen (z. B. eine wissenschaftliche Arbeit mit mehreren Dateien, Forschungsdaten mit verschiedenen Formaten oder eine digitale Edition mit Text, Bildern und Annotationen).
- Es ermöglicht eine strukturierte Wiederverwendung digitaler Inhalte in verschiedenen Kontexten.
Kernkonzept: Aggregationen digitaler Objekte
OAI-ORE beschreibt digitale Ressourcen als Aggregationen:
- Eine Aggregation ist eine Sammlung von digitalen Objekten, die als Einheit behandelt wird.
- Diese kann verschiedene Datentypen enthalten, z. B. PDFs, Bilder, Audio- oder Videodateien.
- Jede Aggregation hat eine "Resource Map", die beschreibt, welche Objekte enthalten sind und wie sie miteinander in Beziehung stehen.
Beispiel: Eine digitale Dissertation könnte folgende Ressourcen enthalten:
- Text der Arbeit (PDF)
- Rohdaten in Tabellenform (CSV oder XML)
- Ergänzende Bilder oder Diagramme (JPEG, PNG)
- Zugehörige Software oder Code-Snippets
Durch OAI-ORE kann diese Struktur als eine Einheit beschrieben und für weitere wissenschaftliche Nutzung bereitgestellt werden.
Technische Grundlage von OAI-ORE
- OAI-ORE nutzt Linked Data Prinzipien und das RDF-Modell, um Objekte und ihre Beziehungen darzustellen.
- Es ermöglicht eine maschinenlesbare Repräsentation der Objekte und unterstützt Formate wie Atom, JSON-LD oder RDF/XML.
- Identifikation erfolgt meist über Persistente Identifikatoren (z. B. DOI, URN, ARK).
Anwendungsbereiche von OAI-ORE
- Digitale Repositorien & Open Access: Forschungsinstitutionen nutzen OAI-ORE, um wissenschaftliche Arbeiten und ihre zugehörigen Daten nachhaltig zu speichern und zugänglich zu machen.
- Digitale Geisteswissenschaften: Projekte wie digitale Editionen oder Archivsammlungen verwenden OAI-ORE, um strukturierte Inhalte für weitere Forschung bereitzustellen.
- Forschungsdatenmanagement: Die Aggregation von Experimenten, Code und Analyseergebnissen in einem reproduzierbaren Format wird durch OAI-ORE erleichtert.
OAI-ORE bietet einen strukturierten Ansatz für die Verwaltung und Wiederverwendung digitaler Objekte. Indem es über Metadaten hinausgeht und digitale Inhalte in ihren Beziehungen beschreibt, trägt es zur langfristigen Archivierung, Zitierbarkeit und Nachnutzung wissenschaftlicher Ressourcen bei. Gerade in Zeiten von Open Science und FAIR-Prinzipien (Findable, Accessible, Interoperable, Reusable) wird OAI-ORE immer wichtiger für den nachhaltigen Umgang mit digitalen Forschungsobjekten.
Linked Open Data (LOD)
Linked Open Data (LOD) ist ein Konzept zur Verknüpfung und freien Bereitstellung strukturierter Daten im Web. Ziel ist es, Daten maschinenlesbar, unter offenen Lizenzen und über standardisierte Schnittstellen zugänglich zu machen. Dadurch können Informationen aus verschiedenen Quellen effizient miteinander vernetzt werden, um neues Wissen zu generieren.
Merkmale von Linked Open Data
- Offene Verfügbarkeit → Daten sind frei zugänglich und dürfen genutzt, geteilt und weiterverarbeitet werden.
- Verknüpfung von Daten → Informationen aus verschiedenen Quellen werden miteinander verbunden, um neue Zusammenhänge zu schaffen.
- Semantische Struktur → Verwendung von standardisierten Metadatenformaten (z. B. RDF, OWL, JSON-LD), um Daten maschinenlesbar zu machen.
- Nutzung von Webstandards → Verwendung von Uniform Resource Identifiers (URIs) zur eindeutigen Identifikation von Dateneinheiten.
Die 5-Sterne-Skala für Open Data (nach Tim Berners-Lee)
⭐ 1 Stern → Daten sind offline oder online verfügbar, aber nicht in einem offenen Format.
⭐⭐ 2 Sterne → Daten sind in einem offenen, maschinenlesbaren Format (z. B. CSV) verfügbar.
⭐⭐⭐ 3 Sterne → Daten nutzen nicht-proprietäre Formate (z. B. JSON, XML).
⭐⭐⭐⭐ 4 Sterne → Daten enthalten URIs, sodass sie miteinander verknüpft werden können.
⭐⭐⭐⭐⭐ 5 Sterne → Daten sind verlinkt mit anderen offenen Datenquellen, um neue Informationen zu generieren.
Vorteile von Linked Open Data
Bessere Auffindbarkeit von Informationen → Durch Verknüpfung verschiedener Datensätze entsteht eine strukturierte Wissensbasis.
Maschinenlesbarkeit → Systeme können Daten automatisch interpretieren und weiterverarbeiten.
Interoperabilität → Unterschiedliche Systeme und Plattformen können durch standardisierte Formate auf die Daten zugreifen.
Ermöglicht neue Erkenntnisse → Kombinierte Datenquellen schaffen neue Zusammenhänge und Wissensnetzwerke.
Offener Zugang → Daten sind frei verfügbar, sodass Wissenschaftler*innen, Unternehmen und die Öffentlichkeit davon profitieren.
Herausforderungen & Kritik
Qualität der Daten → Uneinheitliche Metadaten oder fehlerhafte Verknüpfungen können Probleme verursachen.
Lizenzierung → Nicht alle Datenquellen sind tatsächlich offen und frei nutzbar.
Technische Anforderungen → Die Implementierung von LOD erfordert Fachwissen in Semantic Web-Technologien.
Skalierbarkeit → Große Datenmengen effizient zu verknüpfen und zu verwalten, ist eine Herausforderung.
Beispiele für Linked Open Data
- DBpedia → Extrahiert strukturierte Informationen aus Wikipedia.
- Europeana → Verknüpfung digitaler Kulturgüter aus europäischen Bibliotheken, Museen und Archiven.
- Bio2RDF → Open-Data-Plattform für biomedizinische Daten.
- GND (Gemeinsame Normdatei) → Normierte Datenbank für Personen, Organisationen und Werke in Bibliotheken.
- Wikidata → Offene, vernetzte Wissensdatenbank, die mit Wikipedia und anderen Projekten verknüpft ist.
![]()
Deutsche Initiative für Netzwerkinformation
Die Entwicklung der modernen Informations- und Kommunikationstechnologie verlangt einen Wandel innerhalb der Informationsinfrastrukturen der Hochschulen und anderer Forschungseinrichtungen. Der Umgang mit diesem Wandel ist ein zentrales Thema in der deutschen Hochschullandschaft und setzt mehr als bisher Absprachen, Kooperation, Empfehlungen und Standards voraus. Um diesen Umgang zu koordinieren und zu unterstützen, wurde die Deutsche Initiative für Netzwerkinformation (DINI) eingerichtet. Die Verbesserung der Informations- und Kommunikationsdienstleistungen und die dafür notwendige Entwicklung der Informationsinfrastrukturen an den Hochschulen und Fachgesellschaften soll regional und überregional gefördert werden. Durch Absprachen und Arbeitsteilung zwischen den Infrastruktureinrichtungen kann das Dienstleistungsangebot weiter verbessert werden. Über diese Zusammenarbeit der Infrastruktureinrichtungen hinaus ist die gemeinsame Entwicklung von Standards und Empfehlungen erforderlich.