Digitale Repositorien
Etwas zur Einstimmung :-)
Exhibition. Van Gogh - The Immersive Experience
Ein Repositorum ist ein
- verwalteter Ort zur Aufbewahrung geordneter Dokumente, die öffentlich oder einem beschränkten Nutzerkreis zugänglich sind.
- an Universitäten oder Forschungseinrichtungen betriebene Dokumentenserver, auf denen wissenschaftliche Materialien archiviert und weltweit entgeltfrei zugänglich gemacht werden.
- eine zentrale Ablage für Daten, Dokumente, Objekte und Programme mit ihren Metadaten. (Softwaretechnik)
- ...
Neben den eigentlichen Daten werden im Repository auch die verschiedenen Versionen, Konzeptionen und deren Entwicklungen abgelegt, wodurch alle abgelegten Softwarebausteine mit allen Informationen gespeichert werden. Auf die in Repositories gespeicherten Daten und Dokumente können autorisierte Autoren und Nutzer zugreifen und ändern. Repositories werden im Dokumenten- und Content-Management sowie in der Versionsverwaltung (CVS) eingesetzt. Die Inhalte werden mit Metadaten gekennzeichnet. (http://www.itwissen.info/definition/lexikon/Repository-repository.html 01.2017)
Institutionelle und disziplinäre Repositorien
Als institutionelle Repositorien werden Dokumentenserver bezeichnet, die von Institutionen (meist Universitätsbibliotheken oder Forschungsorganisationen) betrieben werden und ihren Mitgliedern die digitale Publikation oder Archivierung ermöglichen.
Disziplinäre Repositorien hingegen sind institutionsübergreifend und stehen Wissenschaftlerinnen und Wissenschaftlern thematisch gebündelt, z.B. für eine Fachdisziplin, zur Publikation und Archivierung ihrer Arbeiten zur Verfügung (z.B. PsyDok als disziplinären Volltextserver in der [deutschsprachigen] Psychologie oder Social Science Open Access Repository (SSOAR) für die Sozialwissenschaften).
Wie der Zugriff für Nutzende ist auch die Bereitstellung der wissenschaftlichen Publikation für Autorinnen und Autoren auf institutionellen oder disziplinären Repositorien in der Regel entgeltfrei.
Die Scholarly Publishing & Academic Resources Coalition (SPARC), ein Zusammenschluss von Akademien, Bibliotheken und Forschungsorganisationen, empfiehlt den Aufbau wissenschaftseigener Publikationsinfrastrukturen. Auch die Hochschulrektorenkonferenz hat bereits im Jahr 2002 eine Empfehlung herausgegeben, in der die Hochschulleitungen aufgefordert werden, Umstrukturierungsprozesse im Publikationswesen durch Bereitstellung geeigneter Infrastrukturen zu fördern – entweder durch das Betreiben von Hochschulservern oder durch Gründung von hochschuleigenen Verlagen. Inzwischen bieten viele Universitäten und Forschungseinrichtungen ihren Mitgliedern die elektronische Archivierung auf eigenen Dokumentenservern an.
(https://open-access.net/informationen-zu-open-access/repositorien/) 10.2018
Online-Speicherdienste
Zenodo
Der EU finanzierte und durch das OpenAIRE-Konsortium betreute Online-Speicherdienst Zenodo ist hauptsächlich für die Wissenschaft gedacht und speichert wissenschaftsbezogene Datensätze, Software, Publikationen, Berichte, Präsentationen, Videos usw. Die dort gespeicherten Inhalte sind zitierfähig, da sie eine zitierbare DOI haben und der Repository-Dienst GitHub integriert ist. Es gibt eine Integration von ORCID, eine Nutzerstatistik und verschiedene Lizenzoptionen.
Persistente Identifier
Konzepte: URI URN URL Video

Was ist Open Access?
Ziel der Open-Access-Bewegung ist es, wissenschaftliche Literatur und wissenschaftliche Materialien für alle Nutzerinnen und Nutzer kostenlos im Internet zugänglich zu machen. Wissenschaftliche Literatur soll kostenfrei und öffentlich im Internet zugänglich sein, so dass Interessierte die Volltexte lesen, herunterladen, kopieren, verteilen, drucken, in ihnen suchen, auf sie verweisen und sie auch sonst auf jede denkbare legale Weise benutzen können, ohne finanzielle, gesetzliche oder technische Barrieren jenseits von denen, die mit dem Internet-Zugang selbst verbunden sind. In allen Fragen des Wiederabdrucks und der Verteilung und in allen Fragen des Copyright überhaupt sollte die einzige Einschränkung darin bestehen, den jeweiligen Autorinnen und Autoren Kontrolle über ihre Arbeit zu belassen und deren Recht zu sichern, dass ihre Arbeit angemessen anerkannt und zitiert wird.
Möglich wurde die Einrichtung von kostenfreien Dokumentenarchiven durch die Entwicklung der Software EPrints, die es erlaubt, wissenschaftliche Texte so zu archivieren, dass andere Wissenschaftlerinnen und Wissenschaftler entgeltfrei darauf zugreifen und in dem Gesamtbestand recherchieren können. Um eine serverübergreifende Abfrage von Metadaten zu garantieren, gründete sich 1999 die Open Archives Initiative(OAI), die Standards zur effizienten Recherche über verschiedene Server hinweg entwickelt hat.
Ursprünge der Open-Access-Bewegung
Den Grundstein der Open-Access-Bewegung legte Paul Ginsparg, der 1991 den Server ArXiv am Los Alamos National Laboratory (LAN-L) einrichtete, um Preprints in der Physik frei zugänglich zu machen. Weitere führende Akteure und Mitbegründer der Open-Access-Bewegung sind insbesondere Peter Suber, Professor für Philosophie am Earlham College in Richmond/Indiana, und der ungarische Kognitionswissenschaftler Stevan Harnad.
siehe http://open-access.net/de
Open Archives Initiative (OAI)

Die Open Archives Initiative (OAI) ist eine Initiative von Betreibern von Dokumentenservern, um die auf diesen Servern abgelegten elektronischen Publikationen im Internet besser auffindbar und nutzbar zu machen. Dazu werden verschiedene einfache Techniken entwickelt und bereitgestellt, insbesondere das OAI Protocol for Metadata Harvesting (OAI-PMH) zum Einsammeln und Weiterverarbeiten von Metadaten. Als Grundprinzip von OAI gilt die freie Weitergabe von Metadaten.
ROAR
keine Sportauspuffanlage! sondern
Registry of Open Access Repositories (Homepage) der University of Southampton, UK.
ca. 3000 Repositories sind zur Zeit dort registriert.
OpenDOAR
Directory of Open Access Repositories (Homepage) der University of Nottingham, UK.
ca. 3000 Repositories sind zur Zeit dort registriert.
OAI Protocol for Metadata Harvesting (OAI-PMH)
Das XML basierte OAI Protocol for Metadata Harvesting (OAI-PMH) dient dem Sammeln von Metadaten, die von Data Providern bereitgestellt werden. Diese werden von Service Providern aufbereitet und für Suchanfragen im Internet bereitgestellt. Eine derartige Automatisierung kann nur erfolgreich etabliert werden, wenn es eine Einigung über den verwendeten Metadatenstandard gibt. OAI-PMH verlangt Daten, die mindestens dem Standard Dublin Core (DC) entsprechen, empfiehlt aber MARC.
Die Service Provider stellen für die User Suchmaschinen wie OAIster bereit, um die Metadaten einfach und serverübergreifend zu durchsuchen.
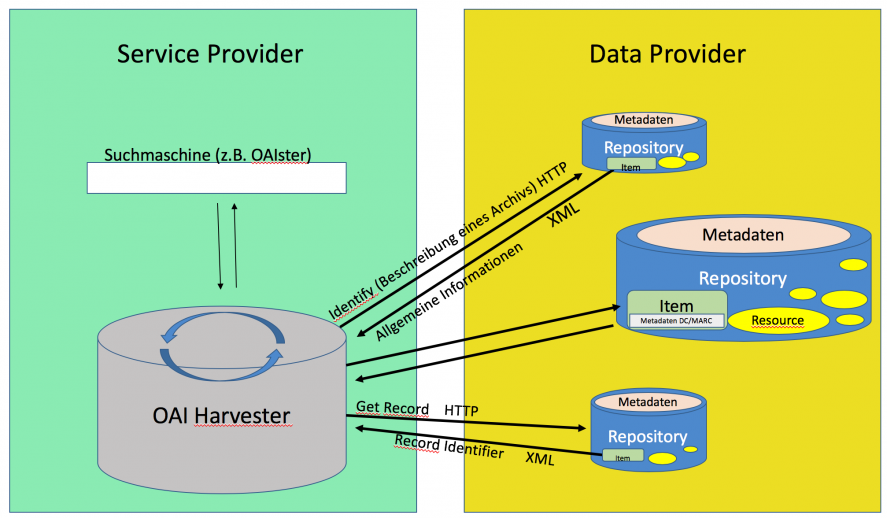
Um auch neueren Medien gerecht zu werden, wird seit 2007 ein Verfahren namens OAI Object Reuse and Exchange (OAI-ORE) geschaffen, das die Metadaten von digitalen Objekten abbilden kann. Dokumente, die als digitale Objekte bezeichnet werden, bestehen aus mehreren zusammengehörenden Dateien, so zum Beispiel verschieden Formate einer Datei (pdf, html, …) oder Übersetzungen oder externe Bilder oder Verknüpfungen oder …. . Es wird eine sogenannte Resource Map angelegt, die diese Strukturen abbildet.
OAIster wurde von der University of Michigan entwickelt und stellt über die Website www.oaister.org eine Suchmaschine zur Verfügung, die die Metadaten von allen Data Providern in Form von durchsucht.
Was sind Linked Open Data?
»Linked Open Data (LOD)« bezeichnet frei verfügbare Daten, die im Internet über einen Uniform Resource Identifier (URI) eindeutig identifiziert und adressiert sind und ebenfalls per URI auf andere Daten verweisen. Die miteinander verknüpften Daten ergeben ein weltweites Netz, das „»Web of Data«„. Um eine möglichst einfache automatische Nutzung der Daten unabhängig von ihrem konkreten Ursprung zu gewährleisten, sollten diese offenen Daten gemäß internationaler »W3C Standards« und nach den „Linked Open Data“ (LOD) Richtlinien im Internet vernetzt werden.
(aus: https://openall.info/formate/linked-opendata/ 3.5.19)
![]()
Deutsche Initiative für Netzwerkinformation
Die Entwicklung der modernen Informations- und Kommunikationstechnologie verlangt einen Wandel innerhalb der Informationsinfrastrukturen der Hochschulen und anderer Forschungseinrichtungen. Der Umgang mit diesem Wandel ist ein zentrales Thema in der deutschen Hochschullandschaft und setzt mehr als bisher Absprachen, Kooperation, Empfehlungen und Standards voraus. Um diesen Umgang zu koordinieren und zu unterstützen, wurde die Deutsche Initiative für Netzwerkinformation (DINI) eingerichtet. Die Verbesserung der Informations- und Kommunikationsdienstleistungen und die dafür notwendige Entwicklung der Informationsinfrastrukturen an den Hochschulen und Fachgesellschaften soll regional und überregional gefördert werden. Durch Absprachen und Arbeitsteilung zwischen den Infrastruktureinrichtungen kann das Dienstleistungsangebot weiter verbessert werden. Über diese Zusammenarbeit der Infrastruktureinrichtungen hinaus ist die gemeinsame Entwicklung von Standards und Empfehlungen erforderlich.
Referat
Das Referat zum Thema Digital Repository sollte mindestens enthalten:
(Präsentation gern bei Ilias hochladen :-) )
- Was ist ein Digitales Objekt?
- Was sind standardisierte Metadaten, was Metadatenmapping?
- Was ist Digital Object Architecture (DOA)?
- Was ist eine in sich abgeschlossene Informationseinheit?
- Was ist ein persistenter Identifier?
- Was ist DOI und FDM?
- Was die NBN (National Bibliography Number)?
- Was sind Repositorien?
- Was ist die Open-Access-Bewegung?
- Was ist SPARC?
- Problem der Sichtbarkeit von Repositorien
- Lösungsversuche (ROAR – DOAR – OAI )
- Was ist das OAI Protocol for Metadata Harvesting (OAI-PMH)?
Welches Problem soll dieses Protokoll lösen?
Was ist ein Data Provider, was ein Service Provider und wie funktioniert das Protokoll? - Was ist OAI Object Reuse and Exchange (OAI-ORE)?
- Was ist Linked Open Data?
- Was ist OpenAIRE?
- Was ist die DINI?
- Was ist OPUS, MyCoRe und EPrints?
- Was ist Zenodo?
- Was ist ORCID?
- Was ist ein Hochschulbibliothekszentrum?
- Was ist GitHub?