Fedora Commons und RDF
Fedora is the flexible, modular, open source repository platform with native linked data support.
=> Flexible Extensible Digital Object Repository Architecture
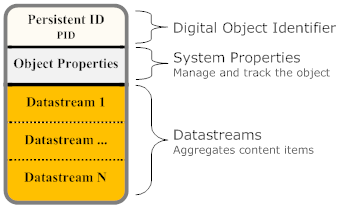
Das Digital Object Model von Fedora
- Das Objektmodell ist immer das selbe, unabhängig davon, ob das Objekt Daten, Verhaltensdefinitionen oder Verhaltensmechanismen beinhaltet. Egal ob es sich um Bilder, Videos oder geografische Informationen handelt: Für Fedora sind sie alle das gleiche (Abstraktion).
- Entwickler können ihre eigenen Content Models entwerfen zur bestmöglichen Repräsentation ihrer Daten (Flexibilität).
- Metadaten und Inhalte stehen in einer engen Verbindung miteinander (innerhalb des Digitalen Objekts).
- Fedora Objekte können Daten referenzieren, die entweder lokal oder auf einem beliebigen über das Internet erreichbaren Server zur Verfügung stehen (Aggregation).
- Die Schnittstellen von Fedora sind erweiterbar, weil Services unmittelbar mit den Daten innerhalb eines Fedora-Objekts assoziiert sind. Wenn sich die Services ändern, ändern sich die Objekte gleich mit (Erweiterbarkeit).

Verteilte Repositorien
- Grundsätzlich geht es darum, über verschiedene Systeme verteilte Repositorien miteinander kommunizieren zu lassen um (1) institutionsübergreifende Zugriffe zu ermöglichen, (2) den nahtlosen Zugriff einer Digitalen Bibliotek auf andere Anwendungen (z.B. Informationsaustausch) zu ermöglichen und (3) große Repositorien zwecks besserer Performanz auf verschiedene Systeme zu verteilen.
Tauglichkeit im Bereich von Archivierung und Digital Preservation
- Fedora-Objekt-XML und das entsprechende Schema werden bei der Einspeisung (der Daten), während der Speicherung und beim Export stets erhalten.
- Versionskontrolle: Da Inhalte versioniert werden, können ältere Versionen digitaler Objekte abgefragt werden.
- Beziehungen zwischen Objekten werden in Form von Metadaten gespeichert. Auf diese Weise können Entwickler verwandte Objekte mit Eltern/Kind Beziehungen verbinden.
- Jedes Fedora Objekt hält eine Liste über alle Veränderungen, die es durchlaufen hat.
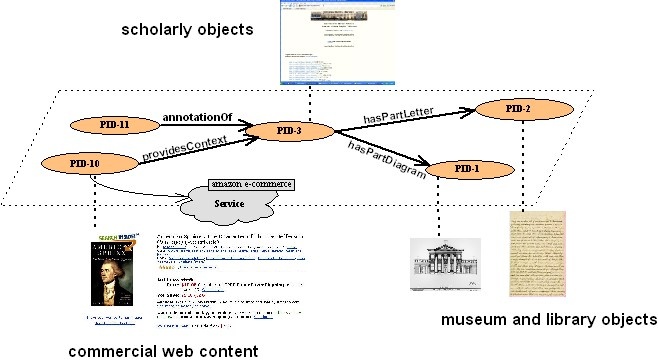
Was sind Fedora Digital Object Relationships?
Grundlegend werden die Interaktionen und Relationen eines Objektes zu der Fedora Umgebung und den weiteren Objekten beschrieben. Es können hierbei vielfältige Beziehungen zwischen den Objekten definiert werden:
- Objekte können sich innerhalb einer Collection anderer Objekte befinden
- Objekte können sich als Bestandteil von anderen Objekten verstehen
- Objekte können voneinander abgeleitet werden
- Objekte können als Beschreibung anderer Objekte dienen
- Objekte können äquivalent zu anderen Objekten sein
- Objekte können dynamische Stellvertreterfunktionen für Web- Content annehmen
- Beziehungen zwischen zwei Objekten können sich jeweils auf weiteren Ebene ausdifferenzieren
- Beziehungen werden durch Metadaten exakter beschrieben
- Allgemeine Beziehungstypen sind in der Fedora relationship ontology definiert
- Zusätzlich kann jede Community eigene Ontologien entwickeln
Warum sind Fedora Digital Object Relationships wichtig?
Die Erzeugung von Metadaten für Fedora Objekte ist die Grundlage für weitreichende Zugriffs- und Managementfunktionalitäten. Beispiele für die Nutzung:
- Das Sortieren von Objekten in Sammlungen zur Unterstützung von Management, OAI harvesting, und Suchfunktionalitäten für den Nutzer.
- Das Definieren von bibliografischen Beziehungen zwischen Objekten.
- Das Definieren von semantischen Beziehungen zwischen Ressourcen um festzuhalten, wie Objekte zu externen Taxonomien oder Standards in Bezug stehen.
- Das Modellieren einer Netzwerk-Ebene, innerhalb derer Ressourcen miteinander verlinkt sind auf der Grundlage von kontextuellen Informationen.
- Das Kodieren/Erzeugen natürlicher Hierarchien von Objekten
- Das Erzeugen von Sammlungs-übergreifenden Verbindungen zwischen Objekten (ein Objekt einer Sammlung kann beispielsweise so auch als Teil einer anderen Sammlung verstanden werden).
Wie werden die Metadaten zu den Digital Object Relationships kodiert?
- Fedora Objekt-zu-Objekt Metadaten werden in XML kodiert – unter der Verwendung des Resource Description Frameworks.
- Die Metadaten müssen einem vorbestimmten Muster (authoring style) folgen
- Das Subjekt wird kodiert unter der Verwendung von
<rdf:Description>. - Die Beziehung ist ein property dieses Subjekts.
- Das Ziel-Objekt wird an das Beziehungs-property unter der Verwendung von dem
rdf:resourceAttribut gebunden. - Als Beispiel für einen Inline XML Datenstrom in Form von RDF können Sie sich hier den Quellcode einer Seite des Fedora Common CMS ansehen (ein wenig nach unten scrollen).
- Das Subjekt wird kodiert unter der Verwendung von
Modellierungsprobleme in XML
“Das Buch‘Semantic Web – Grundlagen’ wird beim Springer-Verlag verlegt?”
<Verlegt>
<Verlag>Springer-Verlag</Verlag>
<Buch>Semantic Web — Grundlagen</Buch>
</Verlegt>
<Verlag Name=“Springer-Verlag“>
<Verlegt Buch=“Semantic Web — Grundlagen“/>
</Verlag>
<Buch Name=“Semantic Web — Grundlagen“>
<Verleger Verlag=“Springer-Verlag“/>
</Buch>
RDF: Graphen statt Bäume
Lösung: Darstellung durch (gerichtete Graphen)
