Verlustfreie Verfahren
- Kompressionsraten bis ca. 50% durch Identifikation von Daten, die sich durch andere Daten ableiten lassen.
- Nach der Dekompression (Dekodierung) steht wieder die vollständige Ausgangsinformation zur Verfügung.
- Je komplexer die Redundanzberechnung, umso kleiner das Datenvolumen und umso größer die Rechenzeit bei der Dekompression.
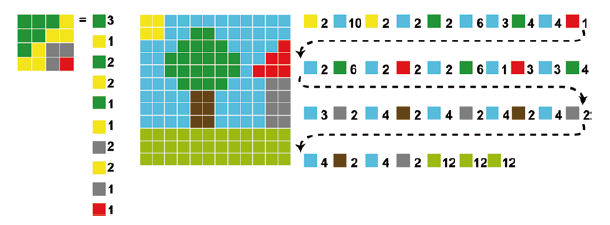
1. Run Length Encoding (RLE)
Lauflängencodierung v. a. für Binärdaten
Dabei werden benachbarte, identische Farbcodierungen zusammengefasst, sodass nur einmal die entsprechende Farbe und die zugehörige Anzahl des Vorkommens abgespeichert werden muss.
Beispiel (einfach):
Ausgangsdatei:
{131, 131, 131, 131, 131, 131, 131, 131, 117, 117, 117, 117, 117, 117, 117, 117}
Zieldatei:
{8, 131, 8, 117}
Speicherbedarf: vorher 16, nachher 4
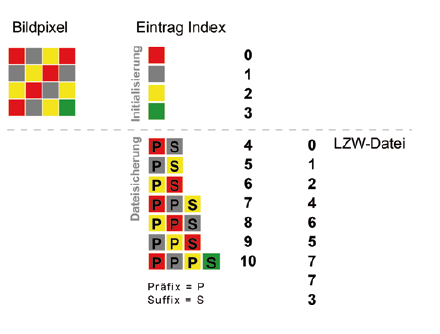
2. Lempel-Ziv-Wels (LZW)
"Wörterbuch"-Algortihmus/ Lookup-Table
Kombinationen, die in der Datei vorkommen, werden mit einem Index versehen, sodass in der anschließenden komprimierten Speicherung nur noch die in der Anzahl reduzierten Indexnummern benötigt werden. Durch Rückführung des Indesxeintrages auf die ursprüngliche Kombination während der Dekompression kann die Originaldatei vollständig wiederhergestellt werden.